Microblogging
Abstract
Twitter & Co. sind ein aktuelles Trendthema im Web. Dieser Beitrag stellt das Phänomen Microblogging vor, beschreibt, warum das Thema ein großes Entwicklungspotenzial aufweist, und nennt zukünftige Forschungsaufgaben.
Einleitung
„What are you doing?“ ist die simple Frage, die der Microblogging-Dienst Twitter seinen Nutzern stellt. Raum für große Erklärungen ermöglicht das auf 140 Zeichen limitierte Eingabefeld nicht. Trotz oder gerade wegen dieser Beschränkung hat der Dienst Statusupdates innerhalb kürzester Zeit als bestimmenden Trend im Web etabliert. Während Twitter in den USA bereits im Präsidentschaftswahlkampf 2008 eine wichtige Rolle spielte, rückte der Microblogging-Service in Deutschland erstmals im Sommer 2009 im Rahmen der iranischen Unruhen in das Blickfeld einer breiten Öffentlichkeit. Zuletzt sorgte der Dienst im Rahmen der Wahlberichterstattung für Aufsehen. Das Phänomen Microblogging muss also schon aufgrund seiner explodierenden Nutzerzahlen und der starken Stellung unter den Web 2.0-Werkzeugen in den Fokus der Forschung rücken. Naheliegende Fragen wie „Warum wird Microblogging genutzt?“ und „Wozu wird Microblogging genutzt?“ führen daraufhin zu Anwendungsmöglichkeiten insbesondere im Unternehmensumfeld, die weit über die Beantwortung der „What are you doing?“-Frage hinausgehen. Der folgende Beitrag stellt zunächst Twitter und das um den Dienst entstandene Ökosystem vor. Anschließend werden das Szenario einer Unternehmensnutzung im Sinne von „Enterprise Microblogging“ und anhand dieses Beispiels die Potenziale der Technologie diskutiert. Ein Überblick über zukünftige Forschungsfragen rundet den Beitrag ab.
Twitter und sein Ökosystem
Aus Nutzersicht erweist sich Twitter (http://twitter.com, „(to) twitter“ ist Englisch und bedeutet „zwitschern“) als ein sehr simples Softwarewerkzeug. Nach Anmeldung kann der Anwender kurze Beiträge (Updates, Postings, „Tweets“) schreiben, die auf dem persönlichen Microblog veröffentlicht werden (vgl. z.B. twitter.com/boehr für den Microblog des ersten Autors). Die Updates anderer Nutzer können abonniert („follow“) werden, woraufhin die individuelle Startseite („Timeline“) eine aggregierte Sicht mit den neuesten Beiträgen des eigenen Netzwerks enthält (vgl. hier und für die folgenden Beispiele Abbildung 1). Nebenfunktionen ermöglichen den Versand privater Direktnachrichten und das Markieren von einzelnen Tweets. Einige Besonderheiten der Twitter-Nutzung haben sich im Laufe der Zeit herausgebildet. So können andere Microblogs durch Verwendung von @<microblogname> referenziert werden. Kürzungsservices dienen der Bereitstellung kurzer URLs (z.B. tinyurl.com/r3mrb9). Beiträge können mittels sogenannter Hashtags mit Schlagworten versehen werden (z.B. „#Microblogging“). Eine letzte Besonderheit ist die Verwendung von “Retweets”, indem Nutzer die Postings anderer erneut posten, wodurch sich wichtige Informationen in Twitter verteilen können (z.B. zeigt „RT @boehr Das ist die Nachricht.“ an, dass der ursprüngliche Beitrag „Das ist die Nachricht.“ von Nutzer „boehr“ stammt).

Diese eigene Twitter-Syntax hat sich über die Zeit aus der Community heraus entwickelt und wurde erst nach deren Etablierung durch das Twitter-Frontend unterstützt (z.B. durch automatische Verlinkung von @boehr mit der entsprechenden Webseite twitter.com/boehr). Diese defensive Entwicklungspolitik hinsichtlich neuer Features ist typisch für Twitter. Der Dienst führt funktionale Innovationen nicht selbst durch, sondern ermöglicht durch seine offene Programmierschnittstelle Drittparteien die Entwicklung eigener, auf dem Microblogging-Dienst basierender, Applikationen. So wurde selbst eine so integrale Funktionalität wie die Suche innerhalb von Twitter-Beiträgen erst 2008 nach Zukauf eines entsprechenden Drittanbieters in die seit 2006 bestehende Kernplattform integriert. Der Kommandozeilenzugriff für die eigene Timeline erfolgt beispielsweise über:
curl -u username:password twitter.com/statuses/friends_timeline.xml
Es stehen verschiedene Authentifizierungsmöglichkeiten zur Verfügung, die API kann neben dem im Beispiel verwendeten XML ebenfalls mit JSON, RSS und Atom antworten. Für viele wichtige Programmiersprachen existieren frei verfügbare Bibliotheken, die die API-Funktionalitäten als einfache Methodenaufrufe implementieren.
Jeder Nutzer kann die API in neue Drittprogramme einbinden. Es existieren hunderte dieser Twitter-Applikationen für die verschiedensten Anwendungsfälle vom mobilen Twitter-Client über Multi-Account-Manager bis hin zu Analysewerkzeugen. Ein Großteil der Nutzer verwendet diese Applikationen, so dass viele Anwender zum „twittern“ nie Twitter selbst aufrufen. Twitter bewegt sich damit immer deutlicher weg von einer Web 2.0-Anwendung hin zur Kommunikations-Middleware.
Enterprise Microblogging
Auf Twitter ist – neben den berühmt-berüchtigten Informationen über das Frühstück oder den Kaffeekonsum – täglich zu beobachten, wie tausende von Menschen ihre Erfahrungen und ihr Wissen teilen. Nicht verwunderlich sind daher Bestrebungen, das Funktionsprinzip in den Unternehmenskontext zu transferieren. Seit 2008 existieren hierfür spezielle Softwarewerkzeuge (wie z.B. Communote, Socialcast und Yammer). Vorhandenen Fallstudien-Untersuchungen haben gezeigt, dass Enterprise Microblogging in der Lage ist, das Informations- und Wissensmanagement in Unternehmen zu unterstützen und insbesondere den Information Overload durch Serien- und Multiempfänger-Emails zu kanalisieren ([2], [4]). Dabei wird insbesondere der Effekt der unerwarteten Nutzungen hervorgehoben, d.h. die gewinnbringende Verwendung einer Information durch einen Dritten, der normalerweise (z.B. im Falle von Email oder Instant Messaging) nicht zum Adressatenkreis der Nachricht gezählt hätte.
Böhringer et al. [4] verdeutlichen in einem Beispiel dieses Prinzip: Der Projektleiter eines Internet-Service-Projekts hatte die Nutzungsbedingungen bei einem Anwalt in Auftrag gegeben. Er dachte allerdings nicht daran, dass dieses Dokument auch auf Englisch verfügbar sein musste. Der Fehler wäre erst Tage später – und damit zu spät – bemerkt worden. Die Benutzung von Microblogging führte hingegen zu folgendem Dialog:
16:41, UserA (Projektleiter): „Telefonat mit #Rechtsanwalt: […] #Nutzungsbestimmungen (AGB), #Datenschutzbestimmungen: Entwurf bis Freitag, Absprache am Sonntag, Feinjustierung Montag […]“
16:52, UserB (Teammitglied): „@UserA macht das der #Rechtsanwalt auch gleich in Deutsch und Englisch?“
Das Teammitglied, welches nur 11 Minuten später den entscheidenden Hinweis gegeben hatte, wäre ohne Nutzung der Microblogging-Plattform nicht in den Prozess eingebunden gewesen.
Entwicklungs-Linien
Realtime
Der Microblogging-Ansatz ist noch sehr neu und es kann zu Recht behauptet werden, dass er sich technologisch noch in den Kinderschuhen befindet. Mit den Initiativen zum Enterprise Microblogging und einigen Open Source-Alternativen ist aktuell zu beobachten, dass sich das Konzept von seinem ersten populären Vertreter Twitter emanzipiert und auch losgelöst von dem Internetdienst betrachtet werden kann. Twitter selbst und viele Analysten gehen davon aus, dass Microblogging einen Schritt hin zum Realtime-Web darstellt, also eine allgemeine Beschleunigung der Informationsvermittlung im Internet. Während Google Informationen erst nach Stunden oder sogar Tagen in seinem Suchindex aufführt, findet die Twitter-Suche sofort aktuelle Nachrichten (so war beispielsweise die erste Nachricht über die Flugzeugnotlandung im Hudson-River inklusive eines Fotos in Twitter zu finden; ein auf einer Fähre am Geschehen vorbeifahrender Twitter-Nutzer hatte die Information mit seinem Mobiltelefon eingestellt).
Ubiquitous Microblogging
Neben dem Ausbau der Echtzeitfähigkeit des Webs kann erhebliches Entwicklungspotenzial der Microblogging-Technologie nicht im „Wie“, sondern im „Wer und Was“ gefunden werden. Unter Millionen von Microblogs finden Nutzer ohne Adressverzeichnis oder organisatorische Zuordnungen für sie selbst interessante Informationsquellen, die sie abonnieren. Twitter kann damit als Werkzeug zur Informationsvermittlung verstanden werden. Sofort stellt sich damit die Frage, ob diese Informationsquellen nur menschliche Nutzer sein müssen oder ob wertvolle Informationen insbesondere im Unternehmensumfeld nicht auch von nicht-menschlichen Informationsquellen stammen (z.B. Maschinen, Software, Prozesse). Abbildung 2 und Abbildung 3 verdeutlichen diesen Gedanken einer allumfassenden Verfügbarkeit von Informationen als Microblogs anhand von existierenden Beispielen in Twitter. Der Sinn dieses Ansatzes kann wiederum mit der bereits diskutierten unerwarteten Nutzung der veröffentlichten Information begründet werden. Insbesondere im Unternehmensumfeld würde dieses Prinzip auf einfache Art und Weise eine Vielzahl von Informationen einer breiten Masse von Anwendern zur Verfügung stellen.

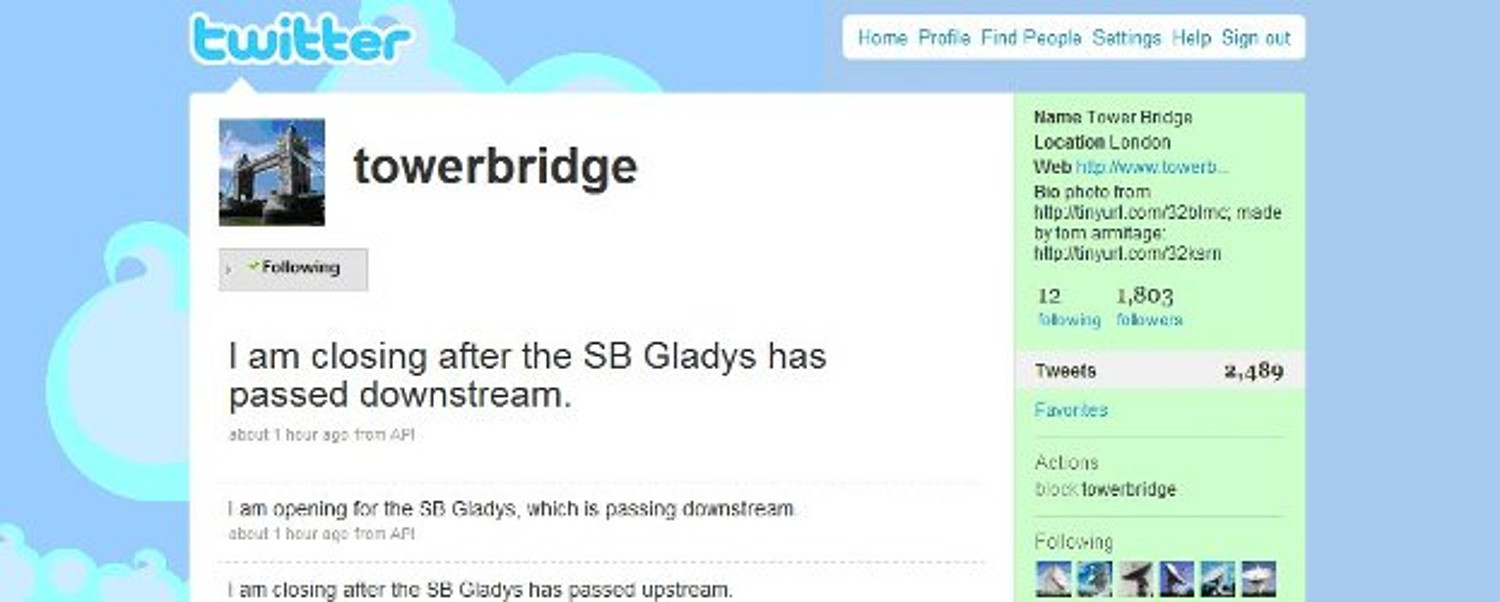
Forschungsfragen
Microblogging wirft eine große Zahl an Forschungsfragen auf und findet entsprechend in steigender Zahl in akademischen Publikationen Beachtung. Dabei finden sich relevante Forschungsgebiete in einem breiten Spektrum von Disziplinen, beginnend bei Kommunikationsforschung über e-Learning und Wirtschaftsinformatik bis hin zu den Betriebs- und Organisationswissenschaften. Aus Sicht der Informatik ist insbesondere die konzeptionelle Weiterentwicklung des Microblogging-Ansatzes und damit die Herausforderung des Realtime-Gedankens bei gleichzeitig großen Datenmengen von Bedeutung.
Auf Seite des Nutzer-Frontends besteht erhebliches Potenzial hinsichtlich der Unterstützung der Anwender bei der sprichwörtlichen Suche im Heuhaufen nach einer subjektiv wichtigen Information im Datenstrom. Es findet sich im Internet eine Reihe von Anwendungen wie z.B. Visualisierungskomponenten für Twitter, die allerdings nicht über einen Prototypenstatus hinausgehen und nicht zu einem integrierten Konzept zusammengefasst sind. Aus wissenschaftlicher Sicht ist dieses Feld bisher wenig beachtet worden. Lediglich Assogba und Donath [1] argumentieren für eine stärkere visuelle Unterstützung des Nutzers und präsentieren eine Plattform für „visuelles Microblogging“.
Ein weiteres Ziel ist die Verbesserung des semantischen Verständnisses der Informationen durch automatische Agents. Passant et al. [9] stellen hierzu ein Konzept für semantisches Microblogging vor. Fraglich bei der Anreicherung von Text mit semantischen Informationen ist dabei vor allem die Nutzerakzeptanz – ein wichtiger Punkt in einem Medium, das auf der Fähigkeit zur schnellen und unkomplizierten Informationspublizierung basiert [3]. Sollte sich die semantische Auszeichnung von Microblogging-Postings als nicht praktikabel erweisen, ist der umgekehrte Weg, das Verständnis natürlicher Sprache durch Text Mining, eine weitere Option [8]. In wieweit Text Mining auf den sehr kurzen und dabei auch oft informellen und möglicherweise mit Syntaxfehlern behafteten Microblogging-Beiträgen ausreichende Erfolgsquoten aufweisen kann, muss zukünftige Forschung zeigen. Erste prototypische Versuche beweisen die grundsätzliche Machbarkeit des Ansatzes (vgl. z.B. die Verwendung von Natural Language Processing bei akibot.com).
Eine bedeutende Forschungsfrage ist die Realisierung eines tragfähigen Architekturkonzeptes für das Microblogging der Zukunft. Passant et al. [9] verwenden in ihrem Konzept für semantisches Microblogging eine dezentrale Architektur, Sandler und Wallach [10] argumentieren ebenfalls gegen einen zentralistischen Ansatz, wie er bei Twitter zu finden ist. Intuitiv kann dem Bestreben zur Dezentralität zugestimmt werden, zumal sich selbige im Web bewährt hat und die Nachteile von Twitters zentraler Applikationsarchitektur durch die starke Verwundbarkeit bei Server-Ausfällen und insbesondere DDoS-Attacken regelmäßig offengelegt wird. Allerdings ist fraglich, ob eine dem Blogging ähnliche Architektur mit einer Vielzahl selbst-gehosteter, dezentraler Microblogs die einfache und schnelle Vernetzung der Nutzer gewährleisten kann, wie sie für Twitter charakteristisch ist. Der dort verwendete kurze Verweis zu einem anderen Microblog mittels der Syntax @ (z.B. @boehr) kann ohne eine einheitliche Applikation oder zumindest ein zentrales Adressverzeichnis wohl nicht in dieser Form weiterverwendet werden. Ob eine ausführliche Adressierung über eine URI (letztlich stellt die Adressierung @ eine Kurzform der URI twitter.com dar, vgl. [3]) ähnlich gut von den Nutzern angenommen werden würde, darf bezweifelt werden.
Der Trend zu Microblogging als Echtzeit-Web mit Millionen von weltweit verteilten Nutzern stellt eine besondere Anforderung an die Verteilungsmechanismen der Information dar, zumal die persistente, maschinenlesbare Bereitstellung der Daten nicht vernachlässigt werden darf (bei Twitter bspw. über REST-Zugriff und RSS). In letzter Zeit sind vor dem Hintergrund solcher Anforderungen eine Reihe von Protokollen entwickelt worden, die persistente Speicherung (mit Möglichkeit zum Pull-Bezug der Informationen) und aktive Realtime-Benachrichtigung (Push-Prinzip) kombinieren (bspw. Pubsubhubhub, Simpleupdateprotocol und RSSCloud). Die Informatik kennt solche Prinzipien schon länger unter dem Titel Publish-Subscribe [7].
Die dauerhafte Speicherung der Datenmengen für Analysezwecke könnte die Nutzung eines speziellen Datenspeichers (Data Warehouse, [5]) erforderlich machen, wobei sich die gewöhnlicher Weise in Microblogging verwendeten Informationen signifikant von klassischen Szenarien unterscheiden (u.a. sind diese qualitativ, nicht aggregierbar und stark bestimmt von der Bedeutung des Faktors Zeit). Das Finden entsprechender Datenstrukturen für ein modifiziertes Konzept eines „Microdata Warehouse“ ist daher eine weitere Herausforderung. Als zusätzlicher Ansatzpunkt für zukünftige Forschung bietet sich abschließend das Complex Event Processing (CEP) an [6]. Jedes einzelne Microblogging-Posting stellt für sich genommen ein Ereignis dar und damit einen potenziellen Input für CEP. Die automatisierte Reaktion auf Tweets setzt wiederum das zumindest teilweise Verständnis dessen Bedeutung voraus.
Fazit
Microblogging hat sich vom belächelten Kurznachrichtendienst innerhalb kurzer Zeit zur ernstzunehmenden Zukunftstechnologie entwickelt, welche in zunehmendem Maße in der Forschung Berücksichtigung findet. Insbesondere die Informatik ist gefordert, durch Anwendung und Integration bereits vorhandener Methoden die Umsetzung der aufgezeigten Zukunftsszenarien (Realtime, Ubiquitous Microblogging) zu unterstützen. Hierzu sind die Leser herzlich eingeladen, den Artikel auf Twitter unter Verwendung des Hashtags „#infspekt“ zu kommentieren und mit den Autoren in Diskussion zu treten (@boehr).
Literatur
[1] Assogba, Y., Donath, J.: Mycrocosm: Visual Microblogging. In: Proceedings of the 42nd Hawaii International Conference on System Sciences, S. 1-10 (2009)
[2] Barnes, S. J., Böhringer, M., Kurze, C., Stietzel, J.: Towards an understanding of social software: the case of Arinia. In: Proceedings of the 43nd Hawaii International Conference on System Sciences, im Druck, (2010)
[3] Böhringer, M., Gluchowski, P., Kurze, C.: Spezifika von Microblogging-Anwendungen als Semantic Web-Applikationen am Beispiel von Twitter. In: Auer, S. et al. (Hrsg.): Agiles Requirements Engineering für Softwareprojekte mit einer großen Anzahl verteilter Stakeholder, Leipzig, 2009
[4] Böhringer, M., Koch, M., Richter, A.: Awareness 2.0 - Ein Anwenderbeispiel von Microblogging im Unternehmen. Information Wissenschaft & Praxis, 60(4), S. 275-279 (2009)
[5] Gluchowski, P.: Data Warehouse. Inf Spekt 20(1), S. 48-49 (1997)
[6] Eckert, M., Bry, F.: Complex Event Processing (CEP). Inf Spekt 32(2), S. 163-167 (2009)
[7] Eugster, P. T., Felber, P. A., Guerraoui, R., Kermarrec, A.: The many faces of publish/subscribe. ACM Computing Surveys 35(2), S. 114-131 (2003)
[8] Hippner, H., Rentzmann, R.: Text Mining. Inf Spekt 29(4), S. 287-290 (2006)
[9] Passant, A., Hastrup, T., Bojars, U., Breslin, J.: Microblogging: A Semantic Web and Distributed Approach. In: Proceedings of the 4th Workshop on Scripting for the Semantic Web (2008) [
10] Sandler, D. R., Wallach, D. S.: Birds of a FETHR: Open, Decentralized Micropublishing. In: 8th International Workshop on Peer-to-Peer Systems (2009).
Autoren und Copyright
Martin Böhringer, Peter Gluchowski
Technische Universität Chemnitz
E-Mail
© 2009 Informatik Spektrum, Springer-Verlag